익명 클래스보다는 람다를 사용하라.


람다식은 추상 메서드 하나인 인터페이스의 인스턴스라고 할 수 있다.
람다보다는 메서드 참조를 사용하라

람다 보다는 짧고 명료한 메서드 참조를 사용해라
하지만, 메서드 참조가 모든 경우에 좋은 건 아니다.

클래스 이름이 너무 길거나, 메서드 이름이 무슨의미인지 명확하지 않은 경우엔
람다가 더 좋은 선택 일 수 있다.
표준 함수형 인터페이스를 사용하라.
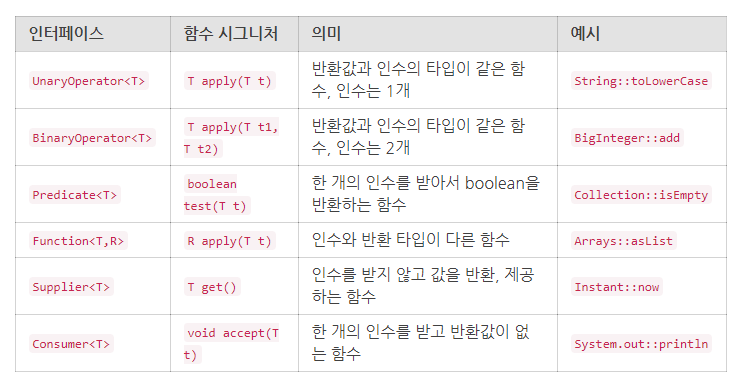
위 6개를 알면 나머지를 유추하기 쉽다.
ex. Unary -> 단항 Binary -> 이항..

예를들어, BiFunction 을 보면 이항 Function으로 볼 수 있다.
T,U 로 인수가 2개 들어오면 R 로 타입이 다른 리턴 값을 내보낼수있다.

와 같은 식으로 사용된다.
흔치는 않지만 직접 함수형 인터페이스를 구현하는게 유리한 경우가 있다.
Comparator 와 ToIntBiFunction 은 구조가 같지만 따로 존재한다.

왜냐면,
1. 자주 쓰이고 이름 자체가 용도를 설명할 수 있을떄
2. 반드시 따라야하는 규약이 있을때,
3. 유용한 디폴트 메소드를 담고 있을때
직접 만들어서 사용할 경우엔 @FunctionalInterface 를 붙여줘야한다.
스트림은 주의해서 사용하라
스트림은 다량의 데이터를 처리하며,
스트림 파이프라인은 수행하는 연산 단계를 뜻한다.
가독성
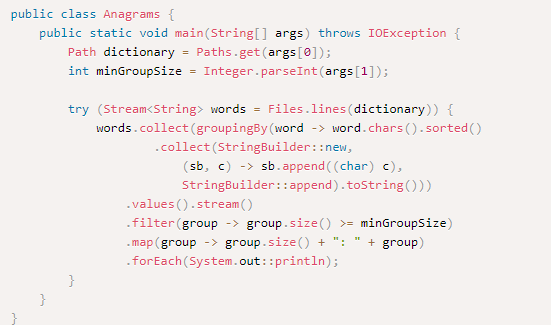
너무 길어지면 가독성이 떨어진다.
적절하게 메소드로 분리해서 사용하는게 좋다.
람다에서는 타입 이름을 자주 생략하므로 매개변수의 이름을 잘 짓는게 중요하다.

코드블록 vs 람다블록
코드 블록에서는 지역변수를 사용할수있지만 람다에서는 final 변수 정도만 읽을 수 있다.

언제 스트림을 사용해야할까?
스트림 파이프라인은 하나의 값이 매핑되면 원래의 값을 잃는 구조다.
- 원소들의 시퀀스를 일관되게 변환하는 경우
- 원소들의 시퀀스를 필터링하는 경우
- 원소들의 시퀀스를 하나의 연산을 사용하여 결합하는 경우(더하기, 최솟값 구하기 등)
- 원소들의 시퀀스를 컬렉션에 모으는 경우
- 원소들의 시퀀스에서 특정 조건을 만족하는 원소를 찾는 경우
한 경우에 스트림을 사용하기 좋다.
스트림에서는 부작용없는 함수를 사용하라
stream 은 함수형 프로그래밍에 기초한 패러다임이다.
각 스트림에서는 재구성을 하는데, 이전 단계의 결과를 받아 처리하는 순수함수여야한다.
순수함수 -> 입력만이 결과에 영향을 주며, 외부의 상태도 변경하지 않는다.

위처럼 forEach 는 함수형 패러다임을 잘 이해하지 못한 경우라 할 수 있다.
모든 연산이 forEach 에서 발생하는데 외부의 결과를 수정하는 람다를 실행하고있다.
forEach는 결과를 보고할때만 쓰는게 좋다.

보통 종단연산은 Collector 를 사용하는게 좋다.
반환 타입으로는 스트림보다 컬렉션이 낫다
Stream 은 iteration 을 지원하지 않는다.

와 같은 방법으로 스트림으로 반복을 쓸 순 있지만,
코드가 난잡해지고, 직관성이 떨어진다.
이런걸 고려했을때 iterable, Stream 을 모두 지원하는 Collection 을 사용하는게 좋다.
스트림 병렬화는 주의해서 적용하라
병렬 스트림은 .parallel() 로 쉽게 사용이 가능하다.
동시성 프로그래밍을 사용할떈 안전성을 항상 생각해야한다.
- 병렬화를 주의해서 사용하지 않으면 오히려 성능이 나빠 질 수 있다.
성능 향상에 최후의 수단으로 사용하자.
- limit 을 사용하면 병렬로 성능향상을 기대할수없다.
어떤때 병렬화를 사용하면 좋을까?>
스트림이 ArrayList, HashMap, HashSet, ConcurrentHashMap 의 인스턴스거나
배열, int, long 일때 효과가 좋다.
- 데이터의 크기를 정확하고 쉽게 나눌수있어서
스레드 간의 분배하기 좋기때문이다.
또한 참조지역성이 좋다는 점에서다. 원소의 참조값이 연속해서 메모리에 저장되어있기때문에
참조지역성이 좋지 않다면 스레드는 데이터가 메인 메모리에서 캐시 메모리로 전송되어 오는것을 기다리는 시간이 늘어서 성능이 나빠질 것이다.
'Java > 이펙티브 자바' 카테고리의 다른 글
| 이펙티브 자바 - 9장 일반적인 프로그래밍 원칙 (0) | 2020.12.29 |
|---|---|
| 이펙티브 자바 - 8장 메서드 (0) | 2020.12.29 |
| 이펙티브 자바 - 6장 열거타입과 애너테이션 (0) | 2020.12.24 |
| 이펙티브 자바 - 5장 제네릭 (0) | 2020.12.23 |
| 이펙티브 자바 - 4장 클래스와 인터페이스 (0) | 2020.12.21 |



