AOP
AOP의 등장 배경과 스프링이 도입한 배경을 알아야한다.
스프링에서 가장 인기 있는 AOP 적용 대상은 바로 선언적 트랜잭션 기능이다.
서비스 추상화를 통해 해결했던 트랜잭션 경계설정 기능을 AOP를 이용해 변경 할 수 있다.
트랜잭션 코드의 분리
UserService에 트랜잭션을 추가했었는데, 트랜잭션 코드가 추가된건 아쉬운 느낌이다.
하지만 논리적으로 비즈니스 로직 전후에 있긴 해야된다.
이 로직들을 클래스로 분리를 시킬 수 있다.
트랜잭션 담당 클래스와 비즈니스 로직 클래스 둘로 나뉘어서
사용하는 곳에서 트랜잭션 클래스를 호출 후 트랜잭션 클래스에서 비즈니스 로직을 호출해서 공존시킬 수 있다.
public class UserServiceTx {
private UserService userService;
private PlatformTransactionManager transactionManager;
public void setUserService(UserService userService) {
this.userService = userService;
}
public void setTransactionManager(PlatformTransactionManager transactionManager) {
this.transactionManager = transactionManager;
}
public void add(User user) {
userService.add(user);
}
public void upgradeLevels() {
TransactionStatus status = this.transactionManager
.getTransaction(new DefaultTransactionDefinition());
try {
userService.upgradeLevels();
this.transactionManager.commit(status);
} catch (RuntimeException e) {
this.transactionManager.rollback(status);
throw e;
}
}
}
의존관계는 이런식으로 형성된다.
UserService 인터페이스를 만들어서 비즈니스 로직은 Impl에서 실행되도록 코드를 짜고
Tx 에서 해당 Impl의 로직을 실행 하는 형태가 된다.

트랜잭션 경계설정 코드 분리의 장점
이렇게 코드를 분리시켜 놓으면 비즈니스 로직에서는 트랜잭션을 신경 쓰지 않고 로직만 짜면 된다.
또 테스트를 손쉽게 만들어 낼 수 있다.
고립된 단위 테스트
가장 좋은 테스트는 작은 단위로 쪼개서 테스트 하는 것이다.
테스트에서 오류가 발생했을때 실행된 코드 양이 많다면 원인을 찾기가 매우 힘들어진다.
테스트는 작은 단위로 하면 좋지만 테스트 대상이 다른 오브젝트와 환경에 의존하고 있다면 작은 단위의 테스트가 주는 장점을 얻기 힘들다.
복잡한 의존 관계 속에서의 테스트

UserService 가 여러 의존 관계를 가지고 있다.
UserService 의 단위 테스트를 하는 것 같지만 실상은 그 뒤에 많은 오브젝트와 환경 심지어 네트워크까지 테스트 하는 셈이다.
그래서 테스트의 대상이 환경이나, 외부 서버, 다른 클래스의 코드에 종속되고 영향 받지 않도록 고립 시켤 필요가 있다.
테스트 대상 오브젝트 고립시키기
테스트를 위한 UserServiceImpl 고립

사전에 테스트를 위해 준비된 동작만 하는 두개의 Mock 객체로 고립된 테스트 대상을 만들 수 있다.
UserServiceImpl 은 기능이 수행돼도 DB 등에 결과가 남지 않으니 작업 결과를 검증하기 어려운데
이럴때는 예를들어 update() 메소드가 호출이 되었는지로 확인을 할 수 있다.
update 를 호출했으면 결국 db에 그 결과가 반영 될 것 이라고 결론 내릴 수 있기 때문이다.
UserDAO 목 객체
public class MockUserDao implements UserDao {
private List<User> users;
private List<User> updated = new ArrayList<>();
public MockUserDao(List<User> users) {
this.users = users;
}
@Override
public List<User> getAll() {
return this.users;
}
@Override
public void update(User user) {
this.updated.add(user);
}
public List<User> getUpdated() {
return updated;
}
@Override
public void deleteAll() {
throw new UnsupportedOperationException();
}
@Override
public int getCount() {
throw new UnsupportedOperationException();
}
@Override
public void add(User user) {
throw new UnsupportedOperationException();
}
@Override
public User get(String id) {
throw new UnsupportedOperationException();
}
}
테스트 수행 성능의 향상
고립된 테스트를 하면 다른 의존 대상을 복잡하게 준비하지 않아도 되니 테스트 수행 성능이 크게 향상된다.
목 프레임워크
Mockito 프레임워크
Mockito 프레임워크를 사용하면 목 클래스를 준비해둘 필요가 없어진다.
간단한 메소드 호출로 테스트용 목 객체를 만들 수 있다.
UserDao mockUserDao = mock(UserDao.class);getAll 메소드가 사용자를 return 하게 구현을 할 수 있다.
when(mockUserDao.getAll()).thenReturn(this .users);- 간단하게 검증도 할 수 있다.
verify(mockUserDao, times(2)).update(any(User.class));
다이내믹 프록시와 팩토리 빈
프록시와 프록시 패턴, 데코레이터 패턴

트랜잭션은 비즈니스 로직과 성격이 다르니 아예 따로 분리 할 수 있다.
여기서 트랜잭션은 분리된 부가기능이 되고 부가기능에서 핵심기능인 비즈니스 로직을 사용하는 구조가 된다.
하지만 문제는 이렇게 사용하면 비즈니스 로직을 직접 사용하면 트랜잭션 기능이 적용되지 않는다는 점이다.
그래서 부가기능은 자신이 클래스인 것처럼 꾸미고 클라이언트가 자신을 거쳐서 핵심기능을 사용하도록 해야 된다.
그러기 위해 클라이언트는 인터페이스를 통해서만 핵심기능을 사용하고
부가기능도 인터페이스를 구현 후 그 사이에 끼어들어야 한다.

이렇게 클라이언트의 요청을 대신 받아주는 대리자, 대리인 과 같은 역할을 하는게 프록시라고 한다.

프록시를 통해 최종적으로 요청을 처리하는 객체를 타깃이라고 한다.
프록시는 사용 목적에 따라 두가지로 구분이 되는데
첫째는 클라이언트가 타깃에 접근하는 방법을 제어하기 위해서 사용되고
둘째로는 타깃에 부가적인 기능을 추가해주기 위해서다.
두가지 모두 대리 오브젝트라는 개념의 프록시를 두고 사용한다는 점이 있지만,
목적에 따라 디자인 패턴에서는 다른 패턴으로 구분한다.
데코레이터 패턴
데코레이터는 런타임시에 타깃에 부가적인 기능을 다이내믹하게 주기 위해 프록시를 사용하는 패턴
마치 제품등을 여러 겹으로 포장하고 장식을 붙이는 것처럼 사용되서 데코레이터 패턴이라 불린다.
데코레이터 패턴에서는 프록시가 하나로 제한되어 있지 않다.
UserServiceTx 부가기능을 제공한 것도 데코레이터 패턴을 적용한 것이라 볼 수 있다.
타깃의 코드를 변경하지 않고, 새로운 기능을 추가 할 때 유용한 방법이다.
프록시 패턴
프록시 라는 용어와 프록시 패턴은 구분 할 필요가 있다.
- 프록시: 클라이언트와 타깃 사이에 대리 역할을 맡는 객체를 두는 방법
- 프록시 패턴: 프록시 중에서도 타깃에 대한 접근 방법을 제어하려는 목적을 가진 경우
프록시 패턴의 프록시는 클라이언트가 타깃에 접근하는 방식을 변경해준다.
타깃에 대한 접근 권한을 제어하기 위해 프록시 패턴을 사용할 수 있다.
다이내믹 프록시
프록시 클래스를 정의하지 않고도 몇가지 API 를 이용해 프록시 처럼 동작 하는 오브젝트를 다이나믹하게 생성해준다.
위의 프록시 구성하고 프록시를 작성하던 것의 문제점은
프록시를 일일이 만들어줘야 하는게 번거롭다는 것이었다.
프록시 생성의 문제점을 알아보기 위해 프록시 클래스를 하나 봐보자
- 타겟 인터페이스
public interface Hello {
String sayHello(String name);
String sayHi(String name);
String sayThankYou(String name);
}- 타겟 클래스
public class HelloTarget implements Hello {
@Override
public String sayHello(String name) {
return "Hello " + name;
}
@Override
public String sayHi(String name) {
return "Hi " + name;
}
@Override
public String sayThankYou(String name) {
return "Thank you " + name;
}
}- 프록시 클래스
public class HelloUppercase implements Hello {
private final Hello delegate;
public HelloUppercase(Hello delegate) {
this.delegate = delegate;
}
@Override
public String sayHello(String name) {
return delegate.sayHello(name).toUpperCase();
}
@Override
public String sayHi(String name) {
return delegate.sayHi(name).toUpperCase();
}
@Override
public String sayThankYou(String name) {
return delegate.sayThankYou(name).toUpperCase();
}
}여기서 문제가 2가지가 생긴다.
- 인터페이스의 모든 메소드를 구현해서 오버라이딩 하게 코드를 만들어야 한다.
- 대문자로 바꾸는 기능(.toUpperCase())이 중복 된다.
다이나믹 프록시 적용
다이나믹 프록시가 동작하는 방식은 아래와 같다.

다이나믹 프록시는 프록시 팩토리에 의해 런타임시 다이나믹하게 만들어지는 객체다.
다이나믹 프록시는 타깃의 인터페이스와 같은 타입으로 만들어진다.
인터페이스를 구현해서 클래스를 정의하는 수고를 덜 수 있다.
프록시 팩토리에게 인터페이스 정보만 제공해주면 해당 인터페이스를 구현한 클래스의 객체를 자동으로 만들어준다.
프록시가 필요한 부가기능을 제공하는 코드는 직접 작성해야한다.
부가기능은 InvocationHandler 를 구현한 객체에 담는다.
InvocationHandler 는 아래 메소드만 가지고 있는 단순한 인터페이스다.
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable;
invoke 는 리플렉션 Method 와 실행시 전달할 파라미터 args를 파라미터로 받는다.
다이나믹 프록시 오브젝트는 클라이언트의 모든 요청을 InvocationHandler 구현 객체의 invoke 메소드로 넘긴다.
모든 메소드 요청이 한 메소드로 집중해서 중복 기능을 제거 할 수 있다.

Hello 인터페이스로 프록시 팩토리에 다이내믹 프록시를 만들어달라고 요청하면
인터페이스의 모든 메소드를 구현한 프록시 객체가 생성된다.
InvocationHandler 인터페이스로 구현한 객체를 생성할때 제공하면 다이내믹 프록시가 받는 모든 요청을 invoke() 메소드로 보낸다. 인터페이스의 메소드가 많아도 모두 invoke 로 처리 할 수 있다.
public class UppercaseHandler implements InvocationHandler {
private final Hello target;
public UppercaseHandler(Hello target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Object result = method.invoke(target, args);
if (result instanceof String) {
return ((String) result).toUpperCase();
}
return result;
}
}다이나믹 프록시 생성은 Proxy 클래스의 newProxyInstance() 를 이용한다.
Hello proxiedHello = (Hello) Proxy.newProxyInstance(getClass().getClassLoader(),
new Class[]{Hello.class},
new UppercaseHandler(new HelloTarget()));두번째 파라미터에 다이나믹 프록시로 구현할 인터페이스를 설정하고 세번째 파라미터에서 InvocationHandler 구현 객체를 넣어준다.
다이내믹 프록시의 확장
InvocationHandler 의 장점은 타깃의 타입은 상관없다는것
리플렉션의 Method를 이용하기 때문에 타깃의 타입의 제한이 없다. (Hello 객체든 다른 객체든 전부 가능)
public class UppercaseHandler implements InvocationHandler {
private final Object target;
public UppercaseHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Object result = method.invoke(target, args);
if (result instanceof String) {
return ((String) result).toUpperCase();
}
return result;
}
}
호출할 메소드 이름, 파라미터 개수등을 알면 부가적인 기능을 적용할 메소드를 선택 할 수 있다.
(method.getName().startswith() 등등..)
예외처리를 하려면 InvocationTargetException으로 포장이 돼서 전달되는데
저 예외로 받은 후 처리
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Object result = method.invoke(target, args);
if (result instanceof String && method.getName().startsWith("say")) {
return ((String) result).toUpperCase();
}
return result;
}
다이내믹 프록시를 위한 팩토리 빈
스프링은 내부적으로 클래스 이름을 가지고 빈 오브젝트를 생성하는데,
문제는 다이나믹 프록시 오브젝트의 클래스 정보를 미리 알아서 스프링 빈에 정의 할 방법이 없다는것
다이내믹 프록시 객체를 스프링의 빈으로 등록할 방법이 없다.
팩토리 빈
스프링은 클래스 정보를 가지고 디폴트 생성자로 오브젝트를 만드는 방법 외에도 빈을 만들 수 있게 제공해주는게 여러가지 있다. 그 중 하나가 팩토리 빈을 이용해 빈을 생성하는것인데, 팩토리 빈으로 스프링을 대신해서 빈을 생성한다.
public interface FactoryBean<T> {
@Nullable
T getObject() throws Exception;
@Nullable
Class<?> getObjectType();
default boolean isSingleton() {
return true;
}
}
팩토리빈은 먼저 프록시를 생성하고 그것을 빈으로 등록한다.
클라이언트가 UserService에 접근하면 그 프록시 객체를 사용하게 된다.
프록시 팩토리 빈 방식의 장점과 한계
프록시 팩토리 빈 방식의 장점
재사용이 가능해서 어떤 서비스에도 붙일 수 있다.
프록시 팩토리 빈 방식의 한계
한번에 여러개의 클래스에 공통적인 부가기능을 제공하는게 불가능하다.
하나의 타깃에만 적용되는 부가기능이면 괜찮지만
트랜잭션 같이 많은 클래스의 메소드에 적용해야 한다면 비슷한 팩토리 빈의 설정이 중복되게 된다.
스프링의 프록시 팩토리 빈
자바 JDK 에서 제공해주는 다이내믹 프록시 외에도 편리하게 프록시를 만들 수 있게 지원하는 기술들이 있다.
스프링에서는 일관되게 프록시를 만들 수 있게 추상 레이어를 제공한다.
스프링에서 제공하는 팩토리 빈은 ProxyFactoryBean으로 프록시를 생성해서 빈 오브젝트로 등록해주는 역할을 한다.
ProxyFactoryBean는 순수하게 프록시를 만드는 작업을 하고, 프록시를 통해 제공할 부가기능은 별도의 빈에서 만들 수 있다.
부가기능은 MethodInterceptor 인터페이스를 구현해서 만든다.
@Test
public void proxyFactoryBean() {
ProxyFactoryBean pfBean = new ProxyFactoryBean();
pfBean.setTarget(new HelloTarget());
pfBean.addAdvice(new UppercaseAdvice());
Hello proxyHello = (Hello) pfBean.getObject();
assertThat(proxyHello.sayHello("Toby"), is("HELLO TOBY"));
}
static class UppercaseAdvice implements MethodInterceptor{
@Override
public Object invoke(MethodInvocation methodInvocation) throws Throwable {
String ret = (String) methodInvocation.proceed();
return ret.toUpperCase();
}
}어드바이스 : 타깃이 필요 없는 순수한 부가 기능
코드를 보면 MethodInterceptor를 구현한 UppercaseAdvice 에는 타깃 객체가 없다.
MethodInvocation은 타깃 객체의 메소드를 실행 할 수 있는 기능이 있기 때문에 부가기능을 제공하는데만 집중 할 수 있다.
JDK 프록시와 스프링 프록시 차이
JDK프록시
final Hello hello = (Hello) Proxy.newProxyInstance(getClass().getClassLoader()
,new Class[]{Hello.class}
,new UppercaseHandler(new HelloTarget())스프링 프록시
ProxyFactoryBean pfBean = new ProxyFactoryBean();
pfBean.setTarget(new HelloTarget());
pfBean.addAdvice(new UppercaseAdvice());
Hello proxyHello = (Hello) pfBean.getObject();
- 차이점을 보면 부가기능을 만드는 클래스에 타겟을 따로 등록 안해줘도 된다는 점.
- Methodlnvocation은 일종의 콜백 객체로, proceed 메소드를 실행하면 타깃 객체의 메소드를 내부적으로 실행 해준다.
- 재사용 가능한 기능을 만들어두고 바뀌는 부분만 외부에서 주입해서 이를 작업 중에 사용하도록 하는 템플릿/콜백 구조다.
- 이렇게 부가기능을 담은 객체를 어드바이스라고 한다.
포인트컷 : 부가 기능 적용 대산 메소드 선정 방법
메소드의 이름을 가지고 부가기능을 적용대상 메소드를 선정하는것을 포인트컷이라 한다.

JDK 다이나믹 프록시 방식은 InvocationHandler 가 타깃과 메소드에 의존하고 있기 때문에
타깃이 다르고 메소드 방식이 다르면 여러 프록시가 InvocationHandler 를 공유 할 수 없다.
InvacationHandler 객체는 특정 타깃을 위한 프록시에 제한이 되어서 빈으로 등록 안하고 계속 생성을 했어야 했다.
이런식으로,
,new UppercaseHandler(new HelloTarget())

반면에 스프링 ProxyFactoryBean 방식을 사용하면
어드바이스와 포인트컷으로 유용한 구조를 가진다.
부가기능을 가지는 어드바이스와 어디에 사용될지 포인트컷으로 정한다.
어드바이스, 포인트컷 모두 공유가 가능하도록 싱글톤 빈으로 등록이 가능하고,
프록시는 어드바이스와 포인트컷을 DI로 주입해서 사용한다. 프록시로부터 어드바이스, 포인트컷을 독립시키고
DI로 사용할것을 주입시키는건 전형적인 전략 패턴이라 볼 수 있다.
Spring Factory Bean으로 어드바이스와 포인트컷을 등록한 예제를 봐보자.
@Test
public void pointcutAdvisor() {
ProxyFactoryBean pfBean = new ProxyFactoryBean();
pfBean.setTarget(new HelloTarget());
NameMatchMethodPointcut pointcut = new NameMatchMethodPointcut();
pointcut.setMappedName("sayH*");
pfBean.addAdvisor(new DefaultPointcutAdvisor(pointcut, new UppercaseAdvice()));
Hello proxyHello = (Hello) pfBean.getObject();
}포인트컷으로 적용될 곳을 지정해주고,
포인트컷과 어드바이스를 묶어서 addAdvisor로 호출한다.
그리고 포인트컷과 어드바이스 이 두개를 묶은 조합을 어드바이저라고 한다.
ProxyFacroryBean 은 스프링의 DI, 템플릿/콜백, 서비스 추상화 등의 기법이 모두 적용되었다.
따라서 어드바이스를 여러 프록시가 공유 할 수 있고, 포인트컷과 자유롭게 조합이 가능하다.
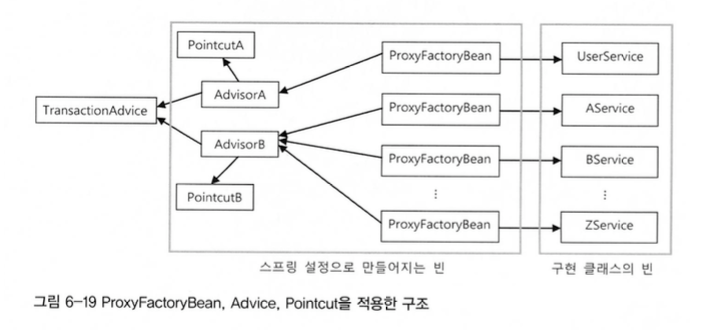
각각 어드바이저가 트랜잭션 어드바이스와 사용될 포인트컷을 묶고 있고,
프록시빈이 해당 어드바이저로 메소드에 어드바이스가 적용되는 모습
스프링 AOP
자동 프록시 생성
처음에 트랜잭션을 구현할때 크게 2가지 문제가 있었는데
1. 타깃 객체마다 프록시를 만들어서 부가기능을 만들어야 했던 이슈.
- (Spring Proxy factory bean) 다이나믹 프록시로 해결 했다. 한 메소드로 기능이 모이게
2. 아직 남은건 부가기능 적용이 필요한 타깃마다 비슷한 내용의 ProxyFactoryBean 설정 정보가 추가된다는것
ProxyFactoryBean txProxyFactoryBean = context.getBean("&userService", ProxyFactoryBean.class);
txProxyFactoryBean.setTarget(testUserService);
UserService userServiceTx = (UserService) txProxyFactoryBean.getObject();
빈 후처리기를 이용한 자동 프록시 생성기

BeanPostProcessor 인터페이스를 이용하는 방법이다.
빈 후처리기는 빈 객체가 만들어지고 난 후에 빈 객체를 다시 가공할 수 있게 해준다.
여기서 사용할게 DefaultAdvisorAutoProxyCreator다.
DefaultAdvisorAutoProxyCreator 는 어드바이저(어드바이스(부가기능)) + 포인트컷) 을 이용해서 자동으로 프록시를 생성하는것이다.
DefaultAdvisorAutoProxyCreator로 자체적으로 빈등록을 하고 빈 객체가 생성될때마다 빈 후처리기에 보내서 후처리 작업을 요청한다.
빈 후처리기에서는 빈객체의 프로퍼티를 수정할 수도 있고 별도로 초기화 작업을 할 수 도 있는데,
이걸 활용하면 빈 객체의 일부를 프록시로 포장하고, 프록시를 빈으로 등록할수있다.
DefaultAdvisorAutoProxyCreator를 빈 후처리기로 등록하게 되면
스프링은 빈 객체를 생성할때마다 후처리기에 빈을 보낸다.
1. DefaultAdvisorAutoProxyCreator는 우선 모든 어드바이저 내의 포인트컷을 이용해 해당 빈이 프록시 대상인지 확인한다.
2. 적용대상이면 내장된 프록시 생성기에서 빈 프록시를 만들고 만들어진 프록시에 어드바이저를 연결한다.
3. 빈 후처리기는 프록시를 생성 후 컨테이너에게 빈 객체 대신 프록시 객체를 돌려준다.
DefaultAdvisorAutoProxyCreator 적용
public class NameMatchClassMethodPointcut extends NameMatchMethodPointcut{
public void setMappedClassName(String mappedClassName){
this.setClassFilter(new SimpleClassFilter(mappedClassName));
}
static class SimpleClassFilter implements ClassFilter{
String mappedName;
private SimpleClassFilter(String mappedName){
this.mappedName = mappedName;
}
@Override
public boolean matches(Class<?> clazz) {
return PatternMatchUtils.simpleMatch(mappedName, clazz.getSimpleName());
}
}
}
포인트컷에서 어떤 클래스에 어드바이스가 작동할지 위처럼 클래스 필터를 설정해주고,
@Bean
public NameMatchClassMethodPointcut transactionPointcut(){
NameMatchClassMethodPointcut pointcut = new NameMatchClassMethodPointcut();
pointcut.setMappedName("upgrade*");
pointcut.setMappedClassName("*ServiceImpl");
return pointcut;
}
포인트컷이 어떤 곳에 들어갈지 설정해주고
@Bean
public DefaultPointcutAdvisor transactionAdvisor(){
DefaultPointcutAdvisor defaultPointcutAdvisor = new DefaultPointcutAdvisor();
defaultPointcutAdvisor.setAdvice(transactionAdvice());
defaultPointcutAdvisor.setPointcut(transactionPointcut());
return defaultPointcutAdvisor;
}
어드바이스를 설정해주면 아래처럼 코드마다 프록시빈을 설정했던 부분을 없앨 수 있다.
ProxyFactoryBean txProxyFactoryBean = context.getBean("&userService", ProxyFactoryBean.class);
txProxyFactoryBean.setTarget(testUserService);
UserService userServiceTx = (UserService) txProxyFactoryBean.getObject();
AOP란 무엇인가.
부가기능들은 객체지향적인 설계 방법으로는 독립적인 모듈화가 불가능했다.
다이나믹 프록시라던지 빈 후처리기같은 복잡한 기술들이 쓰였기 때문에
이렇게 부가기능을 모듈화 하는건 객체지향 설계와는 다른 특성을 가져서
모듈화된 부가기능을 객체라 부르지 않고 Aspect 라고 부른다.
애스팩트는 부가기능을 정의한 어드바이스와 어디에 적용될지 포인트컷을 갖는다.

트랜잭션 속성
트랜잭션 정의
트랜잭션 경계안에 있는 작업은 커밋으로 모두 성공하던지 롤백으로 모두 취소되어야 한다.
이 밖에도 트랜잭션의 동작방식을 제어할 수 있는 몇가지 조건들이 있다.
트랜잭션 전파
트랜잭션 전파는 진행중인 트랜잭션이 있거나 없을때 어떻게 동작할지 결정하는 방식이다.
- PROPAGATION_REQUIRED - 진행중인 트랜잭션이 없으면 시작하고 있으면 참여
- PROPAGATION_REQUIRES_NEW - 새로운 트랜잭션 시작
- PROPAGATION_NOT_SUPPORTED - 트랜잭션 없이 동작
격리수준
모든 DB 트랜잭션은 격리 수준을 가지고 있다.
서버 환경에서는 여러 트랜잭션이 동시에 진행 될 수 있는데 가능하면 트랜잭션이 순차적으로 발생하면 좋지만
그렇게하면 성능이 너무 떨어지게 된다.
따라서 적절한 격리수준을 조정해서 관리해야한다. 디폴트는 ISOLATION_DEFAULT다.
DataSource에 설정된 디폴트 격리수준을 따른다는 뜻.
애노테이션 트랜잭션 속성과 포인트컷
좀 더 세밀하게 트랜잭션을 관리하려고 하면 포인트컷은 한계가 있을 수 있다.
세밀하게 트랜잭션을 관리하다보면 포인트컷 설정파일들이 관리하기 어려워진다.
이렇게 세밀한 트랜잭션 속성 제어를 위해 스프링에 제공하는 다른 방법이 있다.
트랜잭션 애노테이션
@Transaction 애노테이션의 코드는 단순하고 직관적이라서 쉽게 이해할 수 있다.




