Common 을 기반으로 만든 jpaRepository 를 봐보자
boot 를 사용하지 않으면
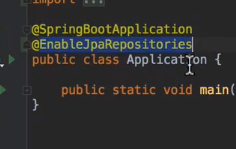
어노테이션을 붙여야 사용가능하다
여기서 BaseRepository 들을 설정 할 수 있다.

@Repository 를 안붙여도 된다 이미 중복
JpaRepository 구현체인 SimpleJpaRepository 에 이미 @Repository 가 들어가있다.
근데 붙어있어야 좋은 이유는 빈으로 등록도 되고

예외를 DataAccessException 으로 바꿔주기 때문
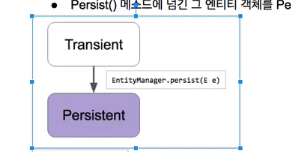
Jpa : 엔티티 저장하기
Transient 상태의 객체면 EntityManager.persist()
Detached 상태면 EntityManager.merge() 가 된다.
Detached 인지 어떻게 판단하는지?
엔티티의 @Id 프로퍼티를 찾아서 id 가 null 이 아니면 Detached 상태로 판단한다

JPA 쿼리 메소드


NavedQuery 는 엔티티 에서 쿼리를 정의해서 쓸 수 있다.
하지만 도메인 엔티티 클래스가 너무 복잡해진다.
이거보다는 사실 @Query 를 쓰는게 좋다
Sort
@Query 에서 Pageable , Sort 를 사용할땐?

Sort는 이렇게 프로퍼티를 줘서 사용한다.

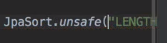
하지만 함수 같은 걸 줄땐 사용이 불가능
이걸 우회하려면
JpaSort.unsafe 라는 메소드를 써서 우회할 수 있다.
Named Parameter

@Param 으로 값을 줄 수 있다.
Update 쿼리 메소드
주로 update 는 persistentContext가 상태 객체를 관리하다가
상태가 변화가 일어났고 변화를 db 에 넣으려고 할때
flush 를 하는데 , 그 때 보통 update 쿼리가 실행이 된다.
그래서 우리가 굳이 update 를 만들어 쓰지 않는다 거의
하지만, 성능 상의 이유로 update 를 너무 많이 호출을 할때
직접 정의 해서 사용은 할 수 있다.

select 쿼리가 아닌 update 라는걸 @Modifying 으로 알려줘야한다.
굳이 줘야하나 싶긴하다
추천 하진 않는 방법이다.

로 update 후 find 를 했는데 여전히 hibernate 로 바뀌지 않아있다.
왜냐?
update 후에 select 를 안하기 때문이다.
왜 안할까?
아직 트랜잭션이 안끝나서 저 spring 객체는 아직 persistent 상태다
1차캐시 즉 persitentContext 가 가지고 있어서
db로 아직 안갔고 저 상태에서 select 를 하면 spring 의 데이터가 나오게된다

이렇게 어플리케이션 로직으로 푸는게 맞다고함
저기선 hibernate 라고 잘 나온다.
spring 객체 1차 캐시에 적용이 되어있기때문에
EntityGraph

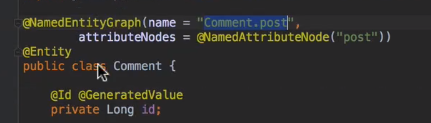
여기서 그룹의 이름은 Commnet.post 고
attributeNodes 에 post 를 설정해놨다

기본값: FETCH 가
설정한 엔티티 애트리뷰트는 EAGER 로 가져오고
나머지 필드들이 LAZY로 가져와진다.
'Spring > jpa' 카테고리의 다른 글
| [spring data jpa] spring data - jpa2 (0) | 2020.12.18 |
|---|---|
| [spring data jpa] spring data common - web (0) | 2020.12.17 |
| [spring data jpa] spring data jpa - common2 (0) | 2020.12.17 |
| [spring data jpa] spring data - Common (0) | 2020.12.17 |
| [spring data jpa] spring data jpa 소개 및 원리 (0) | 2020.12.17 |



